I’m a staff engineer and I’ve spent my career building things in the Saas startup space, at everything from seed-round companies to public giants. The one constant you’ll see anywhere is that if you ask an experienced engineer how to build something, they’ll respond “it depends”, myself included. But “it depends” doesn’t mean there are no rules for how to build something, or that no solution is more correct than any other. Some designs tend to be more correct in any architecture, and that interests me, so I’ve decided to write about the rules I’ve found most useful.
DAGs all the way down
This most useful rule I’ve found in all of software development is that all software should be DAGs (Directed Acyclic Graphs) at all levels. If you’ve got multiple services, if Service A can make calls to Service B, Service B should not be able to make calls to Service A. If you’re building software in layers, if your business layer can make calls to your data layer, your data layer should not be able to make calls to your business layer. Cycles are the enemy, and if you allow them in any form, it’s nearly impossible to not end up with a big ball of mud architecture.
How does this work practically? If you’re building a service oriented architecture or a modular monolith, I like to implement what I call the left-right rule, that is, you should be able to lay out all services (or modules or bounded contexts if you’re into DDD) on a 2d plane such that services are only ever aware of the existence of services on their right. This means services can treat everything to their left as clients, they can take their needs into consideration as users, but they’re never dependent on them and can make no guarantees about them. Likewise services on their right can be treated like upstream vendors, they publish a contract of their API you can depend on, but outside of that you can treat them as a block box. Since service owners don’t need to know the internals of services to your left or right, they can focus on making a service that owns their domain well, and nothing else. I’ve worked at a company you’ve probably heard of where this rule was codified directly into the infrastructure code - in order to deploy a service you needed to give a number between 1 and 1000, and services were only allowed to make API calls to services to their right. This works exactly the same in monoliths. Good monoliths have boundries, and if you’re building your monolith well, then the difference between a monolith and a microservice is just if the calls go over HTTP. You’re still defining contracts between modules via interfaces that take plain data types, and modules should still be able to follow the left-right rule.
In practice this usually means architectures where you have an identity/auth service on the far right and an events/audit log/webhooks service on the far left, with some number of services in the middle that own the domains of whatever service your company provides. In this flow requests only ever go right, while responses and events flow left. Every service depends on auth because without the identity of the current user, you can’t really do anything, and if you want a useful audit log or webhooks you’ll need to subscribe to the event streams of every other service, so your events service needs to know about everything.
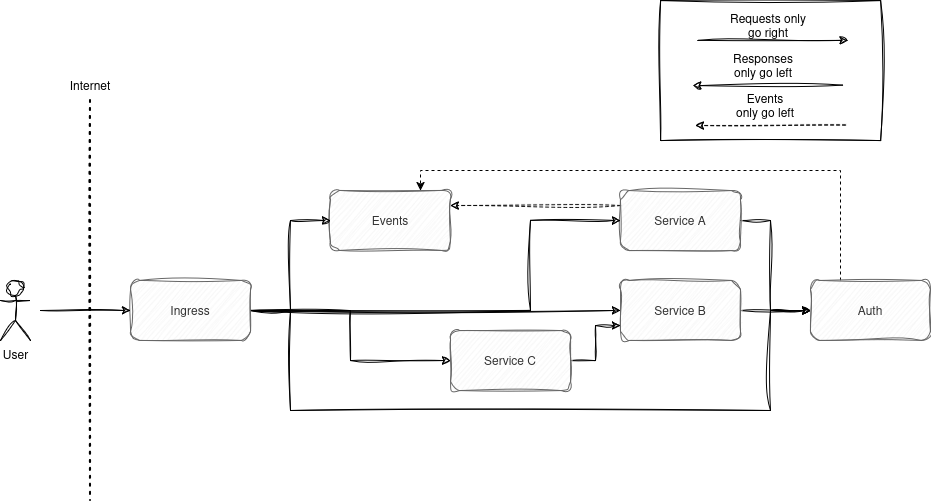
Loose Coupling vs One-way Coupling
I often see people say they want their architecture to be “loosely coupled”, and describe event-driven architectures with a single event bus as a way to achieve that. This approach is something I disagree with, at least without further nuance. Events, much like APIs, are a contract and since my rule is about what services are aware of, it is important to ask who defines the contract? If services can subscribe only to events from services to their right, and the service to the right defines the contract (structure of events is versioned with the owning service) then we’re following the rule above, if not we’re making spaghetti but with kafka and you will forever be juggling event versions between circularly dependent services.
As an example, let’s look at what it would be like to build a Search Service, a service that allows you to search for anything else on the website (products, blog posts, movies, etc.). When a product or blog post is created or updated we want the search service to update its entry, so that we can do full text search on any user query and give them accurate results. Easiest way to do this is have it so that on any update the owning service publishes an event (I’m a huge fan of using the transactional outbox pattern for keeping this atomic), the Search Service subscribes to streams from every other service (which places it all the way to the left). Upon receiving an event, the search service queries optimistic locks its local copy of the entry (event processing should always be concurrency safe), makes a GET request to get the latest copy of the updated entry (event processing should always be idempotent), then updates its local copy (or retries from scratch if the optimistic lock fails). We’ve now created a Search Service that can cleanly rely on any other services without having other services aware that it even exists.
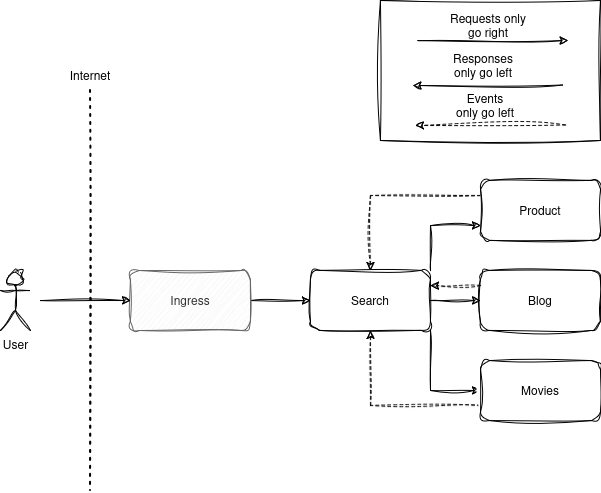
What about results queues, where you process an event from a queue and send an event back with the result? Wouldn’t they have events flowing to the right? True, in this model there theoretically should never be a reason to make a result queue, since you can always just make an API call to the originating service with the result, but so long as the service that first created the event owns the structure of the result such that it doesn’t need to be aware of your service existing (which would also mean any service could publish to that stream) then this works fine in the model.
N-Tier vs Hexagonal vs Vertical Slice Architectures vs Domain Driven Design
I frequently see people arguing over which of these is the “correct” way to build a service. The answer is yes to all of them, they’re different ways of looking at the same problem, prioritizing different things but they’re not actually at odds in any way. Good software is built in layers (n-tier), those layers should have proper interfaces both for dependencies and things that depend on it (hexagonal), and all of those layers should fit inside a domain of code that changes frequently together (vertical slice). Auth is a good example of what should be in a domain. In your generic B2B Saas, you’ve got organizations, users, groups, sessions, and roles owned by an auth service. Let’s look at how we’d build this:
Good software is built in layers. In your classic web app you’ve got 3 layers, presentation (view), business logic (controller), and data (model), with each layer dependent on the ones below it. So you build a data layer that provides CRUD operations to those 5 tables, making sure that any data concerns (e.g. these two entries always need to be updated together) are solved in that layer. The business logic layer takes in the database layer as a dependency, and provides the user operations that you want to expose, dealing with any business logic to do that. The presentation layer takes in the business logic layer, and may just be an API serializer or it may be rendering HTML. Each layer exposes an interface of simple data types, and depends on interfaces from the previous layers.
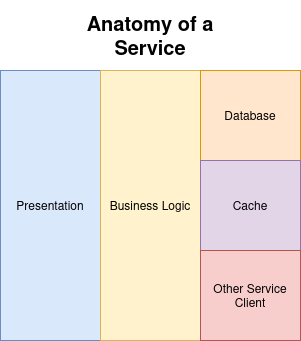
Now I know what you’re thinking.
Ok but what does any of this have to do with DAGs?
Layers are DAGs. Each layer takes in the layers below it, and if you get circular dependencies between layers, you’ve messed up. I write a lot of software that looks something like:
1
2
3
4
5
6
7
8
9
10
11
def main():
config = Config(os.env)
logger = Logger(config)
metrics = Metrics(config)
other_client = OtherServiceClient(config, logger)
db_connection = db.connect(config, logger)
dao = DAO(db_connection, logger, metrics)
cache = Cache(config, logger)
controller = Controller(dao, cache, other_client, logger, metrics, config)
server = Server(controller, logger, metrics, config)
return server.serve("0.0.0.0", 8080)
Where each layer is built on combinations of previous layers, forming a DAG. I’m fairly convinced that the first 100 lines of a program, where you set up your layers and dependencies are the most important lines of the program, because that’s where you wire everything together. This is also why I’m not a huge fan of dependency injection frameworks, they obfuscate what depends on what, and if you can’t keep this section of code clean you have no chance of keeping the rest of your software coherent. This is an idea I take to an extreme in some of my programming language experiments. In every experimental programming language I build I always have one consistent factor, I have the main function of the program take in a World object, that looks something like:
1
2
3
4
5
6
7
trait World {
fn fs() -> FS;
fn net() -> Net;
fn datetime() -> Datetime;
fn console() -> Console;
...
}
The World object represents the software’s only connection to the kernel, to anything outside of the program, you cannot get the current now() time without a reference to world.dateime(), you cannot open a tcp connection without a reference to world.net(), you cannot log without a reference to world.console(). This forces every layer to take in the previous layer in all cases. This means it’s not possible to write software where you cannot trivially mock all IO for test, and it’s not possible to write the equivalent to a malicious NPM package that phones home, because unless you pass it a world.net() you know it cannot do network operations.
It’s DAGs all the way down.