This post is the first in a multipart series talking about practical system design. I’ve read too many system design posts that fail to give strong advice for when to use a given pattern. Instead they offer hand wavy advice, like saying simply to use it where applicable or to use your best judgment. My goal with this series is to give concrete examples of relevant patterns that you can use both in day-to-day work and in system design interviews. This is basically my version of Donne Martin’s system design primer, but covering a wider series of topics.
- Part 1: Data Organization <– You are here
- Part 2 (Coming Soon): API Design
Data Organization is probably the most nebulous topic I’ll cover in this series, as the choices you make here will be determined more by the domain of the problem you’re trying to solve, rather than concrete advice you can use for all problems. I feel it is important to start with it though, as it’ll be the largest determiner of success in your ability to create robust systems. That isn’t to say you will automatically be successful if you pick a good data model and organize your software around it well, but if you pick a bad data model and organize your software poorly you will almost certainly fail in whatever goal you were trying to achieve.
Note that my background is primarily in backend and platform engineering for B2B and B2C SAAS web apps, so that is what this guide will be biased towards.
Data Organization
Data organization is how you break a system down into components. Which components own what data, what data is co-located, and how it can be queried. It is generally the largest factor in determining how complex a system will be. Good data organization can make for extremely flexible and easy to modify systems. Likewise, bad data organization can drastically increase system complexity and a more rigid system that is nearly impossible to modify.
What is a Component?
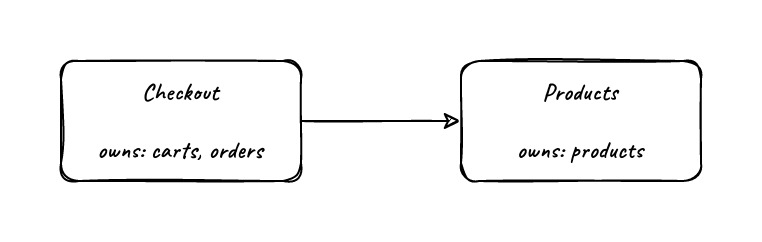
A component is a set of models and co-located code for operating on those models with a well defined interface. A component can be a service in a micro-services architecture, it can be a folder of a monolith (e.g. a django app), or it can be anything that has an interface (e.g. a package in a go app). Which models go together in a component is determined by the base unit of a component which I’ll call a transaction. A transaction could be an RDBMS transaction, such as those in Postgres or MySQL, or they could something like an atomic test-and-set in redis, the defining trait being that changes to models succeed or fail as a group. As an example, let’s take a basic checkout system, that has a products table, a shopping cart table, and a placed order table.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
products
id | name | price |
---+--------+--------
1 | banana | 10.00 |
shopping_carts
id | user_id |
---+---------+
1 | 4 |
shopping_carts_products
shopping_cart_id | product_id | quantity |
-----------------+------------+-----------
1 | 1 | 1 |
orders
id | user_id | shipping_address |
---+---------+-------------------------------------
1 | 4 | 123 Fake St, Springfield, KY 02934 |
order_products
order_id | product_name | quantity | price |
---------+--------------+----------+--------
1 | banana | 1 | 10.00 |
When you go to check out, you want to convert the shopping cart over to the order as a single operation. If there’s a power-loss between deleting the cart and creating the order you lose the order, or if you create the order first then delete the cart a power-loss will cause you to end up with an extra cart will all of the same items. Because this must happen as a single transaction, we can say that the shopping cart model and the order model are part of the same component. On the other hand, shopping carts may be long lived and products may change or even be deleted during the life of a shopping cart, and that’s perfectly valid, we just need remove the lost references when they’re found and prevent checkouts for shopping carts that contain an invalid item. So when we go to check out, our service queries for each of the products and copies their values into the orderproducts table (it never makes sense to update the price of an order _after it’s purchased). Because checking out is dependent on our products model but does not need to be atomically consistant with it we can break this down into two components, with one being dependent on the other.
If you have a set of models where all operations are independent and specific to that model, each model could be it’s own component or you could group them together into a single interface and it would make no difference from a system design perspective. In a monolithic architecture the monolith’s API is such an interface to all models regardless of transactions, even if it’s organized into components internally. I’m going to be using the term service and component interchangably from here on out, so you can assume any point I make about services can be equally applied to components inside of a monolith.
Monolith vs Microservices
One of the most common things I see in system design is the question of whether to go with a monolith vs using micro-services. In reality the answer is that for the most part it doesn’t matter. If done well they work about the same, and if done poorly they both have similar problems with the major day-to-day difference being in how they’re deployed rather than any real data or code organization problems. A well done monolith should more or less look exactly like a micro-service architecture, but rather than using network calls, the monolith uses interfaces that take the same data as network calls.
1
2
3
4
5
6
POST /api/users
{
"username": "myuser",
"password": "hunter2",
"email": "theboringdev@shardingdevnull.blog"
}
vs
1
2
3
type UserComonent interface {
createUser(username string, password string, email string) (User, error)
}
Similarly, if you have a system where all data can be accessed anywhere and things that require live connections like transactions are passed around without any extra thought your system will be difficult to follow regardless of if it’s a micro-service or monolith. Like the unix philosophy, in data organization a component should own one thing well. That doesn’t mean one resource or one table, but rather one “concept” in it’s entirety. What these concepts are is determined by the domain your service is operating in, common examples being an IAM service for handling users/login/keys/RBAC, or an events service that works as an audit-log for all of your other services. Because the service should be as large as required to wholly own a concept “micro-services” tends to be a misnomer, I personally prefer the term “domain-driven service oriented architecture”.
Breaking up a Monolith
The usual advice you see is to start new products with a monolith and move to micro-services when the team is large enough that deployment friction with a monolith becomes a problem. Nearly every company I’ve ever worked for has had a monolith that needed to be split and dedicated resources to it, but it’s a perpetual on-going problem that never really gets fixed. Approaches like “I’ll recreate this portion of functionality in a fresh code base in the new language we’re using” never actually work and can waste significant engineering resources. I don’t recommend trying it, I’ve personally been on projects that have tried that and failed miserably.
Instead the way to split a monolith is the much more simple:
- Create a set of interfaces that represent the set of functionality you’re trying to split out. They should only take in simple data types (numeric, string, date, not file or an active record) that can be eventually moved to JSON, Protobuf, or whatever you’re using to make network requests.
- Create a lint rule that prevents any new code importing from the functionality you’re trying to split out other than your interface. This is important because otherwise you’ll always be trying to convert a moving target. If new code needs to do something not covered by your interface, extend the interface.
- Begin moving existing code to call your interface. If you find that existing code uses your component in unexpected ways modifying your interface is fine, but if you encounter something that deeply relies on your component by needing a reference to a transaction or a file then either your component is the wrong size and you need to move that code as well or you have a bad requirement (see below).
- Once there is zero code that calls you component outside of it’s interface, you can create a stub service with the same API and begin porting code.
If you’re starting with a monolith, and want to make sure you’re not locking yourself in for a painful migration later, a good approach can be to create your interfaces and the lint rules at the start with each new component you’re building. If you find your interfaces are not quite working for your requirements you can make a specific exception to the lint rule and add a comment // TECHDEBT: circular dependency with users to explicitly buy a bit of technical debt in exchange for development speed.
Patterns in Microservices
The Left/Right Rule
One of the biggest sources of unnecessary complexity in a system are circular dependencies. The easiest way to avoid these is to follow what I like to call the left/right rule. You should be able to place all of your system components on a page such that components are only ever aware of services to their right. More specifically:
- Requests only go right
- Responses only go left
This may seem overly simplistic, because it is, but it is sufficient and complete for most real-world systems when used as a modeling technique. From a modeling standpoint there is not a meaningful difference from using a queue or an append-only log like kafka and simply exposing a /events endpoint with “queue clients” holding a cursor to the last event seen and repeatedly querying for new events. This means that queues work just fine under this model, with the caveat that, because services can only be aware of the services to their right, this works more like publish-subscribe since you’ll never be directly sending queue events to another service, just publishing them for any other service that’s interested in them. So when describing the rule, I usually add a third point, though it can be derived from the first two:
- Services can subscribe to published messages of services to their right
Anything like queues that can be modeled to work under this system is fine, even if locally it breaks the rules, so long as the interface it exposes does not break the rules. The one thing to keep in mind if you do that is ownership, if a service on the left cannot read a field in a queue message from a service on the right, the service on the left is always at fault, it’s not the job of the service on the right to care if one of its clients is reading a message wrong, it’s not aware of their existance.
Also note that this description does not allow for an event bus pattern. Event busses that all services have events flow through create a “big ball of mud” architecture since all services depend on the event bus, and the event bus depends on all services.
The Transactional Outbox Pattern
So now we have our system broken into components and defined the dependency tree between them, how do we actually guarantee any consistancy between them. As an example, imagine you have a “search” service that allows you to search through user profiles, blog posts, and product descriptions, each as their own service. Your search service uses ElasticSearch as its data store, keeping a cache of all the relevant data you want to search through. One way to structure this would be to have the users, blog, and product services request to directly update the cache any time their records are updated. This is easy imagine conceptually but tightly couples everything together and adds a problem - what if the search service is down while a blog post is updated? The network call will fail and the search service will never be updated. Similarly, if two updates go through at around the same time, because the search service is not in any kind of transaction with the users/blog/product we may get the wrong version in the cache.
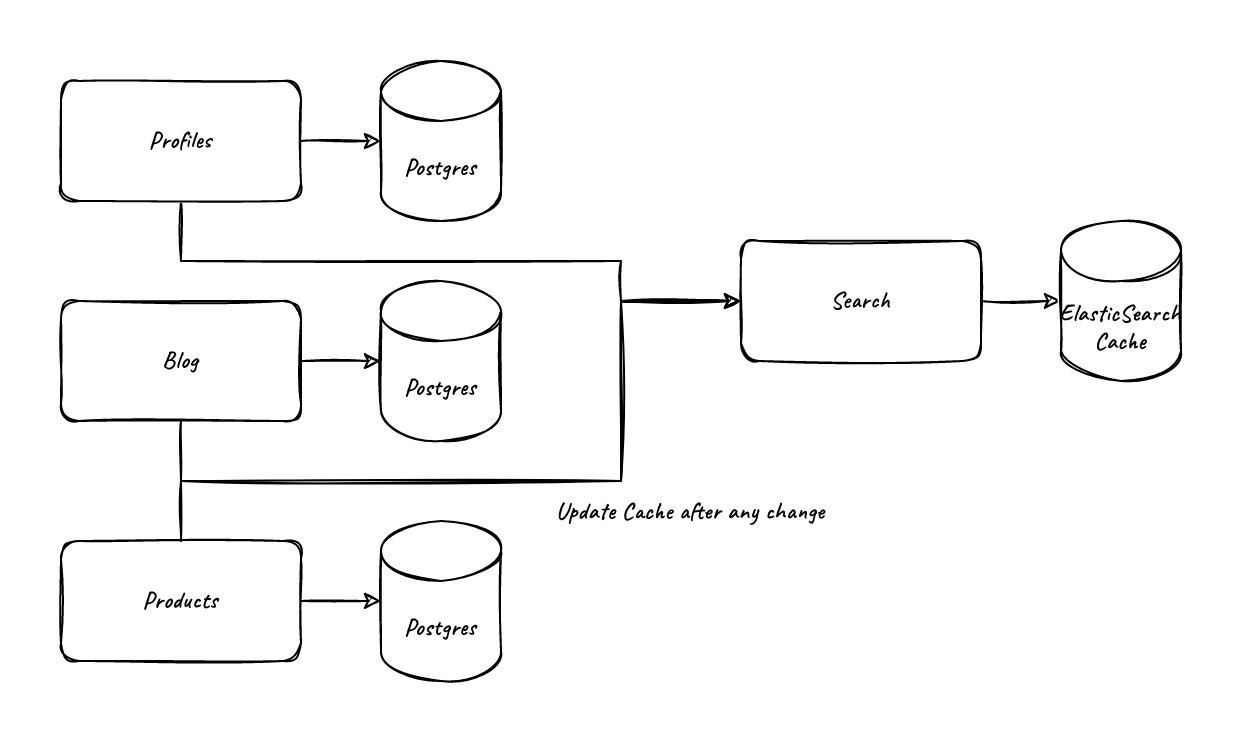
A better option would be to have the cache subscribe for changes in those services. So we update the user profile, blog, and products services so that on change they add a record to an “event log” table as part of the same transaction saying which record was updated. Optionally we’ll have a background service moving those records from the database to kafka or we could just create an API to query the event log directly.
I personally like to structure my event log tables like:
1
2
3
4
5
6
7
change_id: UUID
timestamp: machine time of the update, this can be used to roughly order events
object_type: Enum of Models in the service
change_type: Enum of available changes, e.g. user_create or user_update
changed_by: Id of the user who initiated the change, or the string "SYSTEM" for internal changes
tenant_id: Id of the tenant this takes place in if applicable.
fields_changed: List<String> a list of fields changed, optionally include the to and from values for fields that aren't secrets
Though you should build the structure based on what you need for your domain and subscribers.
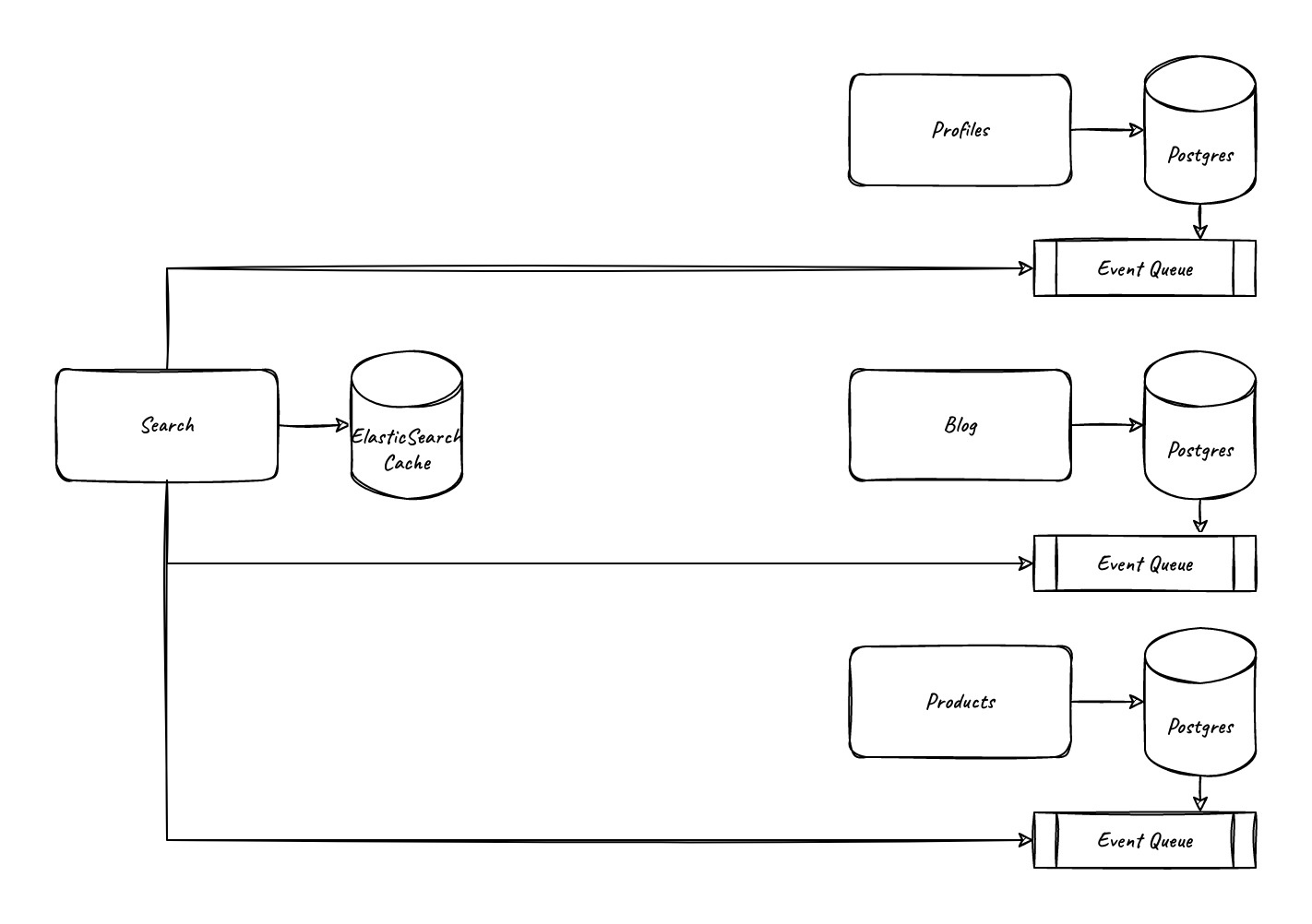
Now the search service will watch the event logs, and any time there’s a new change we will:
- Query the search database to find the current version in the cache.
- Query the users/blog/product services to get the new version.
- Update the record in a concurrency safe manner. (ElasticSearch supports updates via the version parameter).
This means our users/blog/product services no longer need to be aware of the existence of the search service, if any of the other services are down during an update it can retry as many times as we like on any schedule, and if two updates go through at the same time we’re guaranteed to get the latest revision or fail, which can always be retried. This does mean, however that our system is now eventually consistent. In general, at human time scales for the person interacting with this system, this is fine.
It’s important when making these kinds of subscription event handlers to make sure that they’re both concurrency safe and idempotent. If you don’t you’ll only ever be able to run one consumer at a time, or you won’t be able to replay in the event of an outage, which is a recipe for disaster either way. Concurrency safety is generally easy enough to implement either by using transactions or some kind of atomic test-and-set in the data store being written to. Simply query the old version at the start of the transaction, then when you go to write, write only if the data hasn’t changed, this form of optimistic locking guarantees that you’re the only writer and if the handler is idempotent, you can always retry should the write fail. To achieve idempotency, you can simply query the latest version of the data, rather than trusting that what’s in the event is the current state.
This pattern is often called a transactional outbox, because it creates “outbox messages” as part of a transaction for any other service that could be interested in the changes from that transaction. It’s generally one of the most under-utilized patterns in Saas services, as all data is either authoritative, in which case it must be updated as part of a component transaction, or a cache of the authoritative data, in which case cache invalidation can be updated in an eventually consistant manner by watching a transactional outbox.
More info: Transactional Outbox
All Upsteam Services are Managed
Because any service you depend on cannot in this model depend on you, you can treat any upstream service as a managed service. If you’re a search service, is the users service you depend on for authorization an in-house custom micro-service, or a true managed service like Auth0 or AWS Cognito? You don’t have to care, you just use whatever client library is provided to interact with their API, potentially wrapping it in an interface so that your app literally is not aware of which one it’s using, and maybe even uses a mock one during testing.
Splitting Data
Because components are split to wholly own one and only one domain, you’ll occasionally run into situations where part of a record exists outside of the domain that the rest of the record lives in, an example of this is a user preference for a service downstream of your users service. It would be odd for the users service to be aware of this setting because it exists only for a downstream service and services in general should not care about or be aware of downstream services. Likewise it would be odd for that record to exist in the downstream service as it is fundamentally a part of what defines a user in your system. What does it mean if the user exists but doesn’t have a preference set, or if the preference exists but the user has since been deleted? These are considerations you will need to consider if you find yourself in this situation. Basically the choice comes down to three options:
Putting the data all in one service, strongly typed. In the above example, this is equivalent to adding the user preference to the users table in your users service. This is by far the easiest solution, but forces you to pollute the users service with information from other services. This is fine in the short term, but if done repeatedly you can end up with a lot of tight coupling. The users service would now be required to handle any specific requirements about the data from the downstream service.
Putting the data all in one service generically. In the example above this would be adding a “other_data” column to the users service that supports key/value data. This allows you to not pollute your code, but forces all data handling into a cross-service problem and doesn’t work for more complex data.
Splitting the record. In the example above this would be keeping the users table in the users service the same, and adding a user_preference record to the downstream service. The downstream service will now have to handle the case where the user exists but the preference does not, perhaps with a default anywhere the user_preference is used. It will also have to subscribe to user deletion change events from the users service. You might think it would make sense for the downstream service to subscribe to user creation events and auto-create the user_preference record, but because a user could always be created and use the service before the create event goes through. This option is generally a good choice if you are able to support it.
Hexagonal Architecture
A common approach when building components is to use “Hexagonal Architecture” i.e. rather than using your dependencies such as database clients, cache clients, or anything else directly, wrap them in an interface. The common reasoning behind this is that if you create an interface for it you’ll be able to swap out the dependency later with little effort, such as Postgres to MySQL or Memcache to Redis. This is good advice, but not for the reasons listed. In all practicality you’re unlikely to switch backing datastores, and if you do you’ll likely need to change the interface as well, because different datastores offer different features in different ways. It’s useful because it forces you to encode what functionality you’re using into the interface e.g. transactions, batch support, which lookups and writes you’re doing. This makes how you’re using your datastores crystal clear to people learning the code base after the fact, and if you need to change functionality everywhere (e.g. after a write, do X) that can be done entirely in your datastore component. Incidentally, in the unlikely event that you do need to switch datastores, having this information encoded into the interface makes it clear what features your chosen datastore will need which can be helpful even if you do end up having to change that interface.
More info: Hexagonal Architecture On Wikipedia, Netflix Blog
A Bad Requirement
Bad requirements can be a huge driver of complexity in your data organization. A variation of a bad requirement I’ve encountered in real life is:
- Take a generic to-do monolith CRUD service, where todo’s can be assigned to users.
- An existing requirement is that you cannot delete a user while there is still a todo associated with them. The delete request should fail.
- Split out the todo service from the users service.
This is a problem because this requirement creates a circular dependency. The todo is dependent on the user because it has a required user_id field, and the user is dependent on the todo because an operation on the user requires looking up todos. This leaves us with a few options:
- Start a transaction, delete the user, query the to-do service for any to-dos owned by that user and either commit or rollback the transaction depending on the to-do count.
This doesn’t work, as between the query and commit someone else could add a new to-do with the same user. You’ll still get invalid users on to-dos.
- Don’t actually delete the user, just mark them as deleted.
This is a fine solution, but may violate other requirements for security, storage, and GDPR reasons.
- The changes exist inside a transaction, so they must be a single component and we cannot split them out.
This is solving the problem by not solving the problem. If we decide this must be the case for every potentially split out component that we can’t have invalid referenced ids, then we’ll likely end up with our entire application as a single component in a “big ball of mud” architecture.
- Rewrite the to-do code to allow for missing users. If it encounters a user that 404’s, treat it as null/none/unassigned user.
This is probably the best answer, and you can have your to-do app subscribe to your users app to set an actual null value for the user_id, but you need to support and test referencing users that do not exist. This does create a very temporary extra state failure that would be near impossible to test at human scale speeds in a fully setup system, but would be trivial to test with a stub service.
Picking a Data Store
Now that you’ve picked the data boundaries that will define your system, you will need to decide how the data will be stored, queried, and updated. What operations your data store supports efficiently will determine the overall capabilities of your service.
Types
SQL / RDBMS
Examples: MySQL, Postgres, SQLite
SQL is generally the default data store. If you have relations in your data model, an RDBMS is generally going to be the correct choice, even if you use a key/value store elsewhere as a cache. RDBMS’s usually make heavy use of BTree indexes (see below), and support transactions, joins, and foreign keys. They are some of the most flexible data stores out of the ones mention here, and if properly tuned, can scale to huge numbers of queries per second, but do have a hard cap because they run on one node, so can be scaled vertically, but cannot be scaled horizontally without sharding. MySQL and Postgres are generally used as stand alone servers, but SQLite is simply a local file, making it less useful if you’re trying to run a distributed Saas platform but very useful if you need to store a data locally. Use an RDBMS when no other datastore is specifically designed for your use case.
These generally run as single servers, and so represent a single point of failure if data replication is at all behind, but many organizations lie about this fact to themselves to great success, so don’t let this stop you from using them.
More info: Postgres, MySQL, SQLite, Postgres Internals
Key-Value
Examples: Redis, Memcached, TiKV, Etcd, ConsulKV, RocksDB
Key-Value datastores can very efficiently store key-value pairs, with an amortized O(1) time complexity for SET and GET operations. They are often used as caches due to this quick access but many can be used as persistent storage as well. Many relational databases, like TiDB and CochroachDB are built on top of key-value stores (TiKV and RocksDB respectively), storing indexes as a key-value and having those indexes point to a key which you can then use for a multi-key lookup. Some large data storage backends, like AWS S3 are essentially giant key-value stores. Redis and Memcached operate as single nodes, storing data in memory, and distribute data by sharding between them. These are extremely fast for reads and writes, but can be vulnerable to data loss in the event of a crash or power outage. TiKV, Etcd, and ConsulKV are all examples of distributed key-value stores, these aren’t as fast in the in-memory single node ones, but use distributed consensus algorithms like Raft and Paxos so they don’t lose data if a single node goes down. Lastly we have RocksDB which is not it’s own database, but rather an embedded key-value store that you can put inside another program. Use a memory key-value store if have data you want to cache by id, or if you know you’ll never need to support a list operation. Use a distributed key-value store if you need distributed configuration data that cannot tolerate a node going down. Use RocksDB if you’re building another database, or you’re in golang and don’t love the SQLite bindings.
More info: Redis
NoSQL, NewSQL, Document and Wide-Column Stores
Examples: CochroachDB, TiDB, Spanner, MongoDB, DocumentDB, Cassandra / Scylla
These modern types of databases are designed to scale infinitely for specific use cases, can be a super power if you know how to use them, and if you’re reading this you probably don’t need them yet. They’re generally more flexible with data than traditional SQL stores, support distribution, and have nice scaling properties, at the cost of having to know much more about your use-case and schema as they all have different scaling properties, and that support for distribution is not free and it’s easy to hit a massive scaling wall if you don’t plan how your data is distributed to match your use case. Joining data across shards is always a recipe for pain.
For document stores like MongoDB, you’re usually looking at storing JSON documents. MongoDB classically didn’t support joins or transactions, and relied on the user to use atomic operations for row-level concurrency control. This changed in version 4 with adding support for transactions, and the $lookup operator bringing it more in-line with NewSQL databases in how it operates, just with its own query language. The added flexibility with storing JSON documents is as much of a curse as a benefit. You never want to store unstructured data in a document store, so it’s entirely on you the client of the database to enforce the structure. This may mean you have more data migrations than a SQL database if your data structure is evolving at a rapid pace. Use a document store if you absolutely require the data flexibility (though always use some kind of versioned schema), or if you have no use for joins or foreign keys, and your only transactions are multi-create operations, as serializablity gets tricky. A common situation I see that works well for NoSQL stores is when your data is key/value, but you need secondary indexes.
Wide-Column stores, like Scylla and Cassandra are great if you can bucket your data into large numbers of small shards and have a write heavy workload. Discord uses Scylla at massive scale to great success by using combination channel-time buckets as their sharding mechanism, and Cassandra was developed by Facebook for a similar purpose. Use if you’re building a social media site, such as a twitter or discord/slack clone, or something that has the same scaling properties as one.
NewSQL databases, like CockroachDB, TiDB, and Spanner all work similarly, using an LSM Tree to create a key-value store, then implementing a query system on top of that. LSM Trees allow for high write throughput and support fast lookups by key, range queries, and can be iterated over, giving databases all of the tools they need to implement a SELECT statement. Secondary indexes are implemented by pointing at the key of the primary index, so lookups by secondary index are marginally slower because they need two key lookups. The end result is a classical-relational type database that can scale infinitely so long as the shard key is well chosen. A bad shard key can overload a single box, and too granular of a shard key can result in multi-shard queries which are drastically slower. Choose these if you’ve reached the scaling limits of a single traditional SQL box (if you believe this is true, it almost certainly isn’t and you just need to optimize your data structure our queries), if you believe you know exactly how your application is going to scale and can distribute your data correctly from the the beginning (this is likely impossible), or if your application can only exist at scale (requires >10TB of data that must be in relational form just to exist).
More info: TiDB and LSM Trees, Discord and ScyllaDB, Reads and Writes in CockroachDB
Time Series
Examples: Prometheus, InfluxDB
Time series databases or TSDBs store records that have have a timestamp and a value along with some set of labels. These are frequently used for metrics and sensor data, such as recording application health, or sensor data from IOT devices. Most modern TSDBs are heavily influenced by the facebook gorilla paper, which describes an extremely efficient way to store and query metrics. Because the store of individual metrics is so efficient the primary determining factor of scaling for these databases is the cardinality of the labels.
Lets take metrics of an http webapp. If for every instance (you have 100 instances) you want to store the timing data (let’s say 5 timing buckets plus a request count and total time) for each route (45 routes) for each HTTP verb (4 verbs) for each http code (let’s say 5 that you actually use), we’re looking at:
1
2
100 * 7 * 45 * 4 * 5 = 630,000 metrics
and that’s for a relatively small application, in real world scenarios this can easily get up into the millions. This does not include labels like user_id or organization_id as “high cardinality” labels can destroy performance and any efficiency from compression of specific streams.
Note that I’m specifically leaving column stores out of the time series section, column stores can be used for time series data to great effect, but unless you have a need for their power you’re better off using an actual time series data store for metrics data. Using ElasticSearch, tuned for time series settings for structured log data with some subsampling works fine, using it to store basic operational metrics will scale until it doesn’t.
Use TSDBs if you have a need to store metrics or sensor data and have a fixed cardinality.
Column Store
Examples: ClickHouse, ElasticSearch, Druid
Unlike row-oriented stores, such as RDBMS’s and document databases, column stores store their data by column, allowing for rapid operations on ranges of data, usually with the use of vectorized (SIMD) CPU instructions. If you’re looking to sum or average a column on millions of records, this is likely the datastore you’re looking for. Use if you need metrics data with high cardinality and are willing to pay the operating cost for that data.
Search
Examples: ElasticSearch, Solr
Search databases are designed to allow for rapid full-text search of a significant amount of text. These databases often go through a tokenization process at data in-take to allow data to be queried consistently. Words will be de-pluralized, de-hypenated, and lowercased, so that when queried we don’t get “near misses” that exclude relevant search results. Use if you’re building a search function for a product catalog or a blog.
Note that ElasticSearch shows up both here and in the column store category. ElasticSearch can behave very differently depending on how you tune it. I would not recommend default settings ElasticSeach as a column store, and ElasticSearch tuned to be a column store doesn’t work at all for text search.
Append-only Log
Examples: Kafka, Redis Streams
Append-only logs allow you to create a roughly ordered timeline of event data, that consumers can read through. This is different from a queue in two very important ways:
- In the event of an outage, consumers can replay though historical data to catch up.
- Different consumer groups can read though the same data without having to make multiple queues and deal with brokering.
These features are important if you’re following the event log pattern for application design I describe above. They can add sigificant operational overhead if you’re not used to working with these types of tools, so if you are going to use them, take the time to learn them. Use append-only logs if you need to distribute a roughly ordered timeline of event data, and are willing to be both concurrency safe and idempotent in your actions taken as a result.
Object Store
Examples: S3, Google Storage, OpenStack Swift, Ceph, Rook
Object stores store blobs (binary large objects). You can treat them as a remote high-latency, high-bandwidth filesystem of infinite size, though in reality they’re closer to a giant key/value store that allows atomically updating ranges of bytes inside of a value. Two of the most common use cases for object stores are:
- Storing data that’s too large to store in your RDBMS. If you have a profile_picture field on your user object, storing the picture in the database could use megabytes of data per record which would eat through all of your databases RAM. Rather than storing the image in the database you could store the image in an object store and just store the path in your user object. When you need to serve the image, your application queries it from the store and acts as a pass-through.
- Storing append-only log data long-term. You can have logstash send all of your application logs to s3 for long term compliance reasons, as well as to have them accessible to batch processing platforms like spark or flink.
OLAP Databases
Examples: Snowflake
Traditonal SQL databases are sometimes refered to as OLTP (online transaction processing) databases to differentiate them from OLAP (online analytical processing) databases. Sometimes called data warehouses, OLAP databases are not optimized for large numbers of small, rapid transactions but for small numbers of long-running read-intensive queries across huge amounts of data. The most common use-case is for buisness intelligence, with data from your OLTP databases being run through an ETL (extract, transform, load) pipline so that you can have a single source of truth to query for the state of your buisness and how customers are using your product. They can be used in application logic for things like billing, as you have all of your usage data in one place.
Indexes
Knowing how your data is queried can make a significant impact on what queries you make and how to make them. Never query data in an unindexed way if you value your sanity.
BTree
BTree is the most standard type of index you’ll find in databases. With search, insert, and delete of O(log n) you could index every atom in the universe and still only have an average of 273 recursions to find a specific entry, which you could serve in real-time if you could somehow fit the data-set into memory. BTree indexes do not combine, and because it has to recurse over specific fields order matters. An index on:
1
id, organization_id
is entirely different than an index on:
1
organization_id, id
and you would almost never use them for the same query. In general you want any filters you’ll always apply to a query first in the index (as opposed to filters you’ll only apply sometimes dependent the user request), and whatever your sort key is going to be last. So, if there’s a page on your website that displays users inside of an organization sorted by creation date, you’d create the index:
1
organization_id, creation_date
Similarly if you wanted to display a list of todos, optionally filterable by author, by title then creation date (if two posts have the same title) you’d do:
1
title, creation_date
because author is only optionally filterable, and would mess up your sorting if unspecified. But you must always have an index on your ORDER BY, or the database will query everything that could match and try to sort it for you, which is never the behavior you want. It may, however be worth having an additional index on:
1
author_id, title, creation_date
if your application is spending a lot of time filtering authors and you can take the performance hit on insert to have another index, this will depend on the specific usage of your app, and how users are using your search and filter functionality.
Note that I said indexes do not combine, but postgres has a feature that allows index combining. This works by scanning the entirety of both indexes, creating a bitmap from them (see below) and Anding those those indexes together. This can be useful for some large-scale data queries where you need to scan the entire set, but for basic user queries from an API it’s likely not a good choice to rely on it.
More info: Btrees, Postgres index combining
LSMTree
Log-structured merge-trees are a more recent addition to the index space, designed to allow better write throughput by making use of mutiple trees and delayed merging. This index type powers many of the NewSQL implementations, and you should generally consult the docs of whatever database you’re using for best practices.
More info: Understanding LSM Trees
GIN
Postgres allows use of GIN (Generalized Inverted Index) indexes most notably for their support of JSONB. GIN indexes are essentially BTrees that rather than mapping a specific column value to a specific record they map an expression on the record to a list of records. Useful if you want to search on JSON keys or values, or even in a non-json record you want to index on the SUM of two columns. One note is that the current implementation of GIN in postgres does not implement a delete operation for keys on the map, which may not be a problem but is something to keep in mind if you’re planning on indexing a high cardinality field.
More Info: GIN Indexes
Inverted (FST into Roaring Bitmap)
One type of inverted index commonly seen in column stores is a finite-state transducer (FST) pointing at a roaring bitmap. An FST is a very strange data structure compared to most of the other ones in this list. It is essentially an ordered map of strings to integers, and uses a bunch of prefix math to achieve a search complexity of O(k) where k is the size of the largest key in the set. The data structure itself is a form of compression and allows for searching in compressed space, and with the use of finite-state automata allows you to do more complex searches such as regex over the entire set. Because of these properties, it can store huge amounts of data very efficiently, at the expense that the data structure does not allow for in-place updates, and must be re-created every time you want to add a key. This is how ElasticSearch indexes tokens for full text search, with the integer the map is pointing at being the id of a roaring bitmap that it uses for the column store.
Roaring bitmaps are a form of compressed bitmap. Imagine an ordered set of numbers like [1, 7, 53, 125, 126]. Now convert that into a byte-array where you set the 1st, 7th, 53rd, 125th and 126th bits to true and all other bits to false. This is a bitmap. A roaring bitmap takes this bitmap and uses 3 different types of compression on that byte array depending on how dense the numbers are. Long strings of ones and zeros are easy to compress. These data structures are designed to be extremely efficient with And and Or operations and can work with SIMD vectorized operations to allow for extremely fast speeds on modern CPUs.
To see this in practice, imagine a query where you want the sum of a column for every record in a time-frame that matches two tokens. You lookup the two tokens in the FST and it can quickly return to you the two integer ids of roaring bitmaps. You And the roaring bitmaps together and begin iterating over it. For every integer record id coming out of the roaring bitmap, you sum the corresponding record in the column store, using vectorized operations for everything. Because you thought ahead and put all of the records in time order, once it gets to the end of the time-frame you were looking at the database engine can stop querying. This is how ElasticSeach works under the hood for most operational metrics and logging applications.
More info: FSTs, Roaring Bitamps
Design
The order and concurrency of your operations on a database can have a huge impact on the correctness and latency of your application. The classic example of how concurrency can affect correctness is a banking application. Say you have two operations that need to happen at about the same time on one account, one that increments the value adding $10 dollars to the account and one the decrements it, removing $15. The end result is that the account should be down a total of $5, but if the order runs like:
1
2
3
4
5
6
QUERY 1: SELECT value FROM accounts WHERE account_id = 1234; # value 100
QUERY 2: SELECT value FROM accounts WHERE account_id = 1234; # value 100
QUERY 1: 100 + 10 = 110
QUERY 2: 100 - 15 = 85
QUERY 1: UPDATE accounts SET value = 110 WHERE account_id = 1234; # value 110
QUERY 2: UPDATE accounts SET value = 85 WHERE account_id = 1234; # value 85
The final value is 85, rather than the expected 95, because the first query is “lost” due to concurrency. One way to fix this is to change the queries so that they do the increment or decrement inline, with a query like:
1
2
UPDATE accounts SET value = value + 10 where account_id = 1234;
UPDATE accounts SET value = value - 15 where account_id = 1234;
This works because individual row operations are atomic, that is they happen as a single operation. These two statements could run in either order and you’d still get the correct outcome. Sometimes you’ll need to perform operations that involve more than one row, that’s where transactions and locks come in.
Transactions and Atomic Operations
One of the most common scenarios with a database is that you’ll need to query a single record, update it, then write it back. This is the paradigm used by most ORMs application side, and it can benefit from atomic operations to avoid the concurrency operations listed above. One option for doing this is having an “update key” a column that has no other purpose than to control for concurrency through atomic updates. This can be something like a UUID that gets regenerated every time the record is updated, or a version key that gets incremented with every update. When you want to start an operation, you query the current version, then when you want to perform a write you add a WHERE update_key = $old_version clause to your update. If no other operation was operating on that record while you were updating it the write will go through, if something else changed it during that time nothing will be written, and you’ll have to try again. This works well for scenarios where you have few actors to update any given record at a time, but poorly for scenarios where you have many actors trying to update the same record. Because it allows for multiple actors to attempt to operate on the same record at the same time, it is called an optimistic lock, because it’s optimistic that the work being performed under the lock will be able to be committed.
If you’re expecting many actors to be operating on a record or if you need to involve multiple records you’ll need a transaction, which is a kind of pessimistic lock. Pessimistic locks will only every allow one actor to be operating on a set of records at one time, which allows you to have much more control over the order in which operations run, at the the cost of locking being more expensive. In the example above you could run:
1
2
3
TRANSACTION 1: SELECT value FROM accounts WHERE account_id = 1234; # value 100
TRANSACTION 1: 100 + 10 = 110
TRANSACTION 1: UPDATE accounts SET value = 110 WHERE account_id = 1234; # value 110
1
2
3
TRANSACTION 2: SELECT value FROM accounts WHERE account_id = 1234; # value 110
TRANSACTION 2: 110 - 15 = 95
TRANSACTION 2: UPDATE accounts SET value = 95 WHERE account_id = 1234; # value 95
The transactions could run in either order, but because all three operations always run in order together there is no risk of getting the wrong result. Depending the transaction isolation of the transaction the database will lock any rows you access until the end of the transaction, which may be exactly the behavior you want, but if you do any high latency operations while the lock is held (such as querying another service) nothing will be able to access those records until the lock is freed, and you can get a massive latency spike in your application.
Transaction Isolation
The SQL standard defines four levels of transaction isolation, Read Uncommitted, Read Committed, Repeatable Read, and Serializable. These act as modes that your transactions can run in and determine how the database will behave when dealing with multiple concurrent transactions. Read Uncommitted is the weakest, and allows your transaction to experience what are called “dirty reads”, i.e. data that has been written by another transaction but not yet committed. Read Committed does not allow for “dirty reads” but does allow for “nonrepeatable reads”, that is, if your transaction queries the same value twice, it may get different results depending on if other transactions have committed. Repeatable Read obviously does not allow for “nonrepeatable reads” by keeping the old value around for you to query, either through MVCC or an undo log (see below). Repeatable Read does however allow for “phantom reads”, which is when a transaction can see the result of a query change due to other transactions being committed, e.g. adding a row that is not “locked” by the transaction, that row show up in subsequent “SELECT” queries. Serializable does not allow “phantom reads”, and must have the same end result as running the transactions one at a time in some order. This is the strongest level of isolation, but this effect is generally achieved by locking entire ranges of rows, and only allowing one-at-a-time access to them. This can be incredibly useful if your application requires that level of isolation, but can absolutely destroy the performance of your application if you need that concurrency.
While these specific isolation levels are part of the SQL spec, these problems exist in all database solutions. Consult the documentation of the database you’re using to see what properties transactions actually give you and what operations are considered atomic.
Atomic Operations in Redis
Some databases like redis, have entirely different sets of atomic operations from something like SQL. Redis runs single threaded, so every individual operation is always atomic. If you need multiple operations to be atomic together redis supports the pipeline operation, which runs queries together as a single atomic operation. Redis even supports running lua scripts which are themselves atomic, again because redis is single threaded.
The problem with using pipelines for atomic operations in redis comes when we attempt to scale redis via clustering. Clustering is the most common way to scale redis, but because it’s almost entirely a client-side concept (with redis servers being chosen by the hash of the keys being operated on) redis does not support atomic operations across clusters. This can be fine if all of your operations in a pipeline affect the same key, which is commonly the case, but you’ll need to structure your application around this limitation or switch to a distributed key/value store like etcd that has higher latency due to needing distributed consensus.
Sometimes you’ll need something that resembles a transaction, something where you can lookup the current value, query an external service, modify that value and put it back. This is a common case when redis is used as a cache. Redis does not support SQL-like transactions but it does support MULTI, EXEC, DISCARD, and WATCH. WATCH watches a key and allows you to fail out if something modifies the value out from under you. This forms an optimistic lock as stated above, and depending how you structure your application, a combination of atomic pipelines and optimistic locks generally allow you to get what you’d need out of a transaction without needing full transactional semantics.
Undo Log vs MVCC
For databases that support rolling back transactions and isolation modes like repeatable read, the database will need the ability to serve multiple versions of a record at the same time. Some databases, such as MySQL do this through maintaining an undo log. Databases that make use of an undo log will immediately write the new value over the old one when there is a change (assuming the new message fits in the old space), but store the old version in a segment of the table so that it can be rewritten in the event of a rollback or if a transaction with high isolation needs to be able to see that old value. This works well in cases where it is uncommon to rollback transactions, and where you aren’t using high levels of isolation so won’t see any performance hit for the indirection to lookup the undo version’s value. Undo logs are also easy to delete as they are just mapped to pages in memory.
Some databases such as Postgres utilize multi-version concurrency control (MVCC) to support these features. In MVCC every record is written fresh every time it’s updated, and the old version is maintained until it is no longer accessible by any transaction, at which point they may be cleaned up by a periodic background vacuum process. This works well in cases where rollbacks are common or where you need strict isolation levels, but uses significantly more space and requires that vacuum process.
CAP
The CAP theorem states that, in the event of a network partition, a distributed datastore must choose between consistency (every read receives the most recent write) and availability (every request receives a response, even if it’s not the most recent write). This is extended by the PACELC theorem, which states that, even when the system is running without a network partition, a distributed datastore must chose between latency and consistency.
Which of these tradeoffs you want for your application depends entirely on what the requirements for application are. If you’re building a user preferences service, and must have it so that if a user sets a preference, it never reverts, picking consistency in all cases may be the correct choice. Likewise if you’re building a recommendation service, displaying slightly out of date product recommendations to a user might be completely fine, so long as they can always be served reliably and fast. Some datastores allow you to configure which of these properties you need, while others have them baked in.
Weak Consistency
Weak consistency is a form of “best effort” consistency. After a write, reads may or may not eventually be able to see it. This usually allows for extremely fast systems at the cost of losing all guarantees around ever seeing your data again.
/dev/null is an excellent weakly consistent datastore, it can “store” an unlimited amount of data and can process it near instantly. Getting the data back does tend to be problematic, however.
Eventual Consistency
An eventually consistent system is one that, after a write, reads will eventually see the new value. This commonly seen is systems where databases will asynchronously replicate to read-replicas that run slightly behind the primary, or in systems that use a cache with a short TTL. After the cache expires, the new value will then be seen by reads.
Most eventually consistent systems update data in time-scales too short for humans to notice, but can be easily seen by other systems that do a write immediately followed by a read.
Strong Consistency
A system is strongly consistent if after a write, all reads immediately return the new value. This is commonly seen in RDBMSs and other systems that support transactions. This is generally the slowest of the types of consistency as, if the datastore is a distributed system, the systems must form a consensus on what the new value is so they can serve it.
Replication and Fail-over
A common strategy to maintain database availability is to run multiple nodes, so that if one goes down the system can immediately fail-over to another node. If you’re already using read-replicas, in the event that a primary goes down you can promote one of the read-replicas to be the new primary, acting as a “hot standby”. This will ensure that your service is available, but without guaranteeing that the replica is caught up on replication you can loose all of the writes between where the replica is at and where the primary was when it went down. Some systems solve this by allowing you to specify that it must be written to at least some number of nodes before acknowledging the write, such that you would only lose data if you lost that many nodes at once. MongoDB supports this through “write concern”, MySQL supports this through group replication consistency. Enabling this can significantly slow down writes as they need to be replicated across the network, but gives you strong protections against data loss.
Other systems support this through allowing a multi-primary replication configuration. This “just works” on systems that use distributed consensus to determine which writes have been committed, but for systems like MySQL allowing writes to multiple primaries allows for conflicts if you receive different writes on different primaries, and requires a conflict resolution mechanism that may require you to arbitrarily pick which one “wins” if you don’t want to lose data.
Sharding
Sometimes the amount of data you need a datastore to hold, or the number of writes you are seeing go above what a single node can support, even scaled as vertically as you can. When this happens, we can continue scaling by splitting the data between multiple nodes, sharding the data between them. There’s generally two strategies when picking on how to shard data, hashing a unique key (like a uuid primary key) and splitting based on that hash, or picking a non-evenly distributed “shard key” and hashing based on that.
Hashing a unique key results in evenly distributed hashes, which should result in relatively even distribution. This generally prevents most hot-spotting (where one node receives a disproportionate amount of traffic) and makes it easy to re-banance nodes by adjusting the hash ranges each node covers, but has the downside that you’ll need to query every node and combine the results to get the answer to any query besides a specific record lookup by id. If you want to perform a list query on an index to get 100 results across 10 nodes, you’ll need to query potentially up to 1000 records, throwing away 900 results.
Splitting via a shard key will cause an extremely uneven distribution, you’ll need much more active management of how data is balanced across nodes to avoid hot-spotting, but potentially allows you to skip querying every node if you know the shard key you’re looking for. If your data is naturally split via something like tenancy, using tenant_id is a shard key will allow you to always know what node to go to. This strategy can potentially run into a hard scaling wall if one shard key results in too much hot-spotting and a single node cannot cover all of the data in that key.
Many modern NoSQL and NewSQL databases will automatically shard data for you, some automatically doing the first strategy, while some allow you to pick. Because these databases are sharding-aware some can use the full index rather than needing a separate index-per-node and combining the results at the end. Always read the docs on how any database supports sharding before attempting to use it.
Joins
Most database systems are built from two components, a set of indexes that map values to record ids, and a key/value store that maps record ids to the record data. Joins on an index are generally quite fast and it can be useful to think of them as second query pipelined to the first with the data automatically merged by the database rather than an RDBMS specific concept.
1
SELECT * FROM orders INNER JOIN customers ON orders.customer_id = customer.id;
could be rewritten as
1
2
SELECT * FROM orders;
SELECT * FROM customers WHERE id IN (1, 2, 3); # id list from the first query
which, if you’re using redis for caching could again be re-written as
1
2
3
SELECT * FROM orders; #SQL
MGET 1 2 3 # Redis multi-get on the customer ids
NoSQL databases are often stated to not support joins, but they do support running multiple queries, and if they support pipelining queries you can build your own join support by doing the secondary lookups as their own query. This is how you do joins in MongoDB via the $lookup pipeline operator, but it can be extended to things like single node redis if you’re willing to use lua scripts.
Foreign Keys
One of the key features that RDBMSs support (and many Document/NoSQL DBs do not) is foreign keys. Foreign keys allow you to have the database guarantee that another record you’re referencing exists. They act as a safeguard around application logic to make sure that you don’t accidentally create invalid data, and with the CASCADE DELETE option allow you to automatically remove any data referencing something you’re deleting. Foreign keys are almost never used at scale, as the safeguards have a performance hit that isn’t technically necessary if your application is working properly (you can do the checks application side), and if you CASCADE DELETE records with a large amount of associated data, you can lock up the database and degrade performance for everyone. They can also be limiting in how flexible your data can be. Foreign keys generally do not work if you’re sharding.
Another edge case pops up with foreign keys around schema migrations. Gh-ost, GitHub’s schema migration tool for MySQL allows you to make schema modifications without massive table locking by creating a background table, doing the migration there while it is empty, copying over the real data and replaying the binary log to get it up to date, before finally swapping the tables and deleting the original. This workflow cannot fundamentally work if your application uses foreign keys, and the tool does not support them.
For small scale applications, I would still generally recommend using them. They’re a good safeguard against some terrible data corruption bugs. I’d also generally recommend moving from CASCADE DELETE to a throttled background delete job as soon as your application has scale where that could come up.
IDs
What type of primary key is best for an RDBMS table depends largely on how you plan to use that table. Auto-incrementing numeric primary keys are the classic default, tend to be very efficient for storage, and because the numbers are next to each other, bulk inserts generally end up in the same memory page in the index, allowing for more efficient writes. The downside of these is that they’re inherently guessable, if you see a url like /posts/12465 you can assume that there are 12464 posts before this one, even if you don’t have permissions to see them, this allows users to guess at other ids to see if there’s any data your api is unintentionally leaking and tells your competitors exactly what scale you’re running at. Numeric ids also do not work if sharding is used in any way, multiple nodes would need to coordinate to determine the next id.
Version 4 UUIDs are another common approach, they are generally unguessable, can be generated by clients, and have no problems being sharded. The tradeoff is that they’re less space efficient, and because they’re random bulk-writes will be evenly distributed across memory pages, requiring larger fsyncs to disk.
ULIDs and KSUIDs try to bridge the gap between the two by having a time-based component creating strictly orderable UUID-like keys. They are less guessable than auto-incrementing integers, but can be guessable if you generate multiple of them in a short timeframe. The ids are sortable, so they will end up next to each other in an index which can be efficient for writes, but this is a form of intentional hot-spotting so it may not work for every application, but can be excellent if you’re planning on using a BTree like an append-only log.
I’d generally recommend using UUIDs unless you have a specific reason not to.
Table Segments and Timeseries
A common approach to representing time-series data in an RDBMS is to use table segments. Table segments act as an internal (on one node) form of sharding data by time, allowing you to query only the shards within the time range you’re looking for, while still allowing BTree indexing for filters on the data. The duration for how long to make a segment depends heavily on how much data you have and the size of the time range you plan on querying over. If you plan on keeping 90 days worth of data, going by day may mean that you have to search through huge amounts of data to find what you’re looking for if your average query only cares about data from the last 10 minutes. Likewise, if you go by hour and your queries tend to cover multiple days, you won’t be getting the most efficient use of your BTrees.
Practical Example: Building a pastebin clone
When doing these kinds of system design problems, always start by calling out your functional and non-functional requirements.
Functional Requirements:
- Users can sign up and login with a username and password.
- Users can CRUD posts that show up under their account. You must be logged in to post.
- Posts can be a maximum of 1MB in size.
- Users can search posts by text from their account or globally.
- Users can see in the activity page of their account any logins or post updates.
- On user delete, we should remove all of their posts.
Non-functional Requirements:
- We can assume the read-to-write ratio for these posts is high, but some posts will receive significantly more traffic than others.
- Search should be accurate for 99.9% of changes within 5 minutes. This means that search doesn’t have to be 100% accurate to the text instantly, if 100% was expected, this would constitute a bad requirement.
- We can assume extremely low traffic to this service, we will ramp up this requirement once we have a working service.
- This service should have 99.9% uptime. User activity should not be able to cause downtime. This requirement is here so that we have some SLO (service level objective) for the service, a requirement that will affect how we do user deletes.
Data Model
I always recommend starting with the data model, basically everything you do will flow from that. In this model we have users and posts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
User:
id: UUID
username: String
email: String
password_hash: String
created: Timestamp
updated: Timestamp
Post:
id: UUID
author: UUID
text: String
created: Timestamp
updated: Timestamp
Event:
id: UUID
timestamp: Timestamp
user: UUID
resource: Enum(user, post)
event_type: Enum(user_create, user_delete, user_update, user_login, post_create, post_update, post_delete)
fields: Jsonb
Since it’s probably easier to understand the event model with an example, a query to /events might return:
1
2
3
4
5
6
7
8
9
10
11
[
{
"id": "c6b44ad8-c208-416b-8292-a60b421a50bf",
"timestamp": "2022-12-07T04:37:30+00:00",
"user": "c6b44ad8-c208-416b-8292-a60b421a50bf",
"resource": "user",
"event_type": "user_update",
"fields":
[{ "field": "username", "from": "tgilesbie", "to": "TheBoringDev" }],
},
]
User Management
Now that we have data model lets start with users. Authn/Authz are cross-cutting concerns so they’re usually left out of system design problem, because they would be a part of every problem. We could just hand-wave here and say we’re using a managed service for this, but instead let’s hand-wave and say we’re building out basic user creation, forgot password, user deletion, and login behavior. Users are stored in Postgres, and when a user is created or deleted, an event is created as part of the same transaction.
For session handling we’ll do a key/value store like redis holding a json session object, and the unguessable key is sent down as a cookie to the user, with a middleware adding the session object to the request context on each request. On session creation we’ll create an event before the write to redis so that even in the event of a power outage instant failure, we’ll still record the event even if the user never got a chance to use it. I’ll go more into session management in a future article on API design, but this is fine for now as it is not the focus of the problem.
We’ll surface the activity page via a /events endpoint, that returns events for the logged in user.
Posts
Let’s move on to posting now. As our non-functional requirements say we’re starting super small scale and scaling up, we’ll start by just saying posts are also stored in postgres, and we’ll use postgres’s full text search features or an ILIKE statement for searching. On post create/update/delete calls we create an event as part of the same transaction. For the scale we’re operating at we won’t need caching.
User Delete
For the user delete, you may think that just CASCADE DELETE’ing the posts would work, and for a real world system I probably would just do that and mark the fact that we did as tech debt. But if we want to meet the SLO requirement, we actually cannot do this. There is no limit to the number of posts a user can create, so a user can create a large number of posts then delete their account locking up the database to do an indeterminate amount of work. If done repeatedly and maliciously user actions could bring us below the SLO which must not be allowed to happen. Instead we’ll change our post API so that it can either handle having a non-existent user returning null for that field, or automatically hide posts from deleted users until they’re deleted. We’ll then start moving events into something a background worker can pull from such as kafka or redis streams, and delete posts as a background task rate limited so that we don’t tip over the database and interrupt customer traffic.
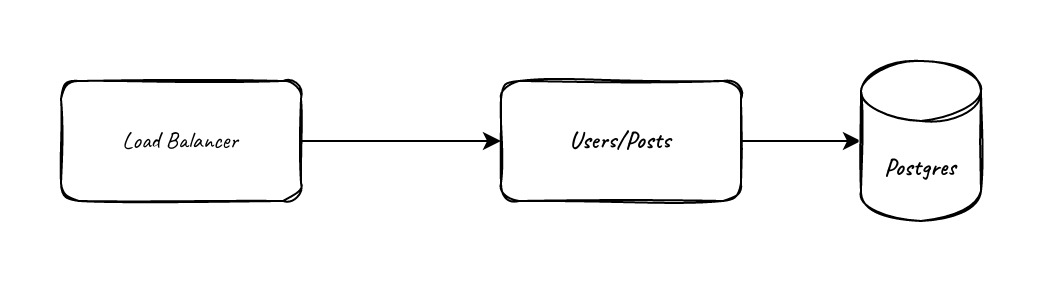
Let’s scale it up
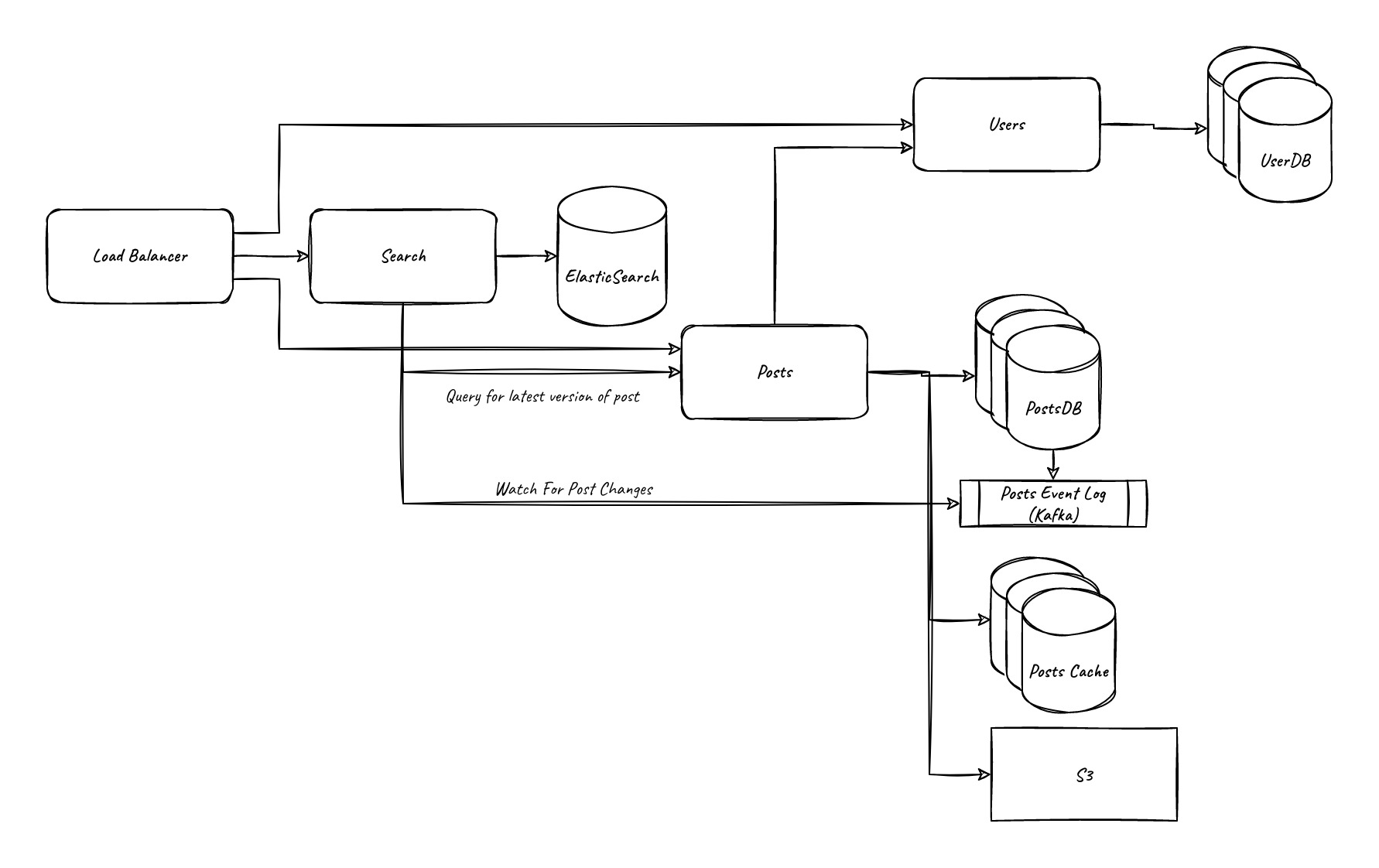
Already, let’s increase the traffic ten-fold. What needs to change?
The first constraint we’ll probably run into is database load on the searching. Text search is very expensive and there are specialized tools for that, so let’s use them. We’ll add a new “search” component that has an ElasticSearch datastore and a worker that listens for post_create, post_update, and post_delete events, and when it receives one, looks up the current version of the document in the cache (if any), looks up the current version in the database, then writes if and only if the current version in the cache still matches. This version of atomic test-and-set guarantees that we’ll either write the latest version or fail, and if we fail we can always retry the event because we’re idemponent (we always look up the latest version from the database, so it can be run any number of times in any order) and concurrency safe (from the atomic test-and-set).
At this point we may also want to introduce some caching. If we find that a few posts are generating most of the requests, it may be worth adding a key/value cache for the posts, with a key of the post id. We can use the atomic test-and-set behavior in redis to get the same concurrency and idempotency guarantees as above in ElasticSearch, but this does introduce a problem. If our search cache is querying our posts service, if it hits the posts cache it may get an out of date post, if that cache has itself not been updated. That leaves us with the following options:
- Introduce a way for the search service to bypass the cache, either via an API flag or a separate API.
This works, our queries here are nearly exactly one-read-to-write with the only exception being concurrency causing retries. We just need to make sure that we don’t expose that functionality publicly.
- Put a delay on processing events in the search service.
This also works, a 30 second delay means the cache will generally be updated, and since we don’t have a 100% guarantee in our requirements that the cache is up to date in the odd chance that with concurrent tasks the post cache takes more than 30 seconds to update we’d still be within our SLA. We can add once daily background task to scan over the entire cache and make sure it’s up to date if we want to make sure we eventually catch that case.
- Have updating the cache create its own event stream which the search service reads from.
This only works if you write the event after updating the cache, as if you write it before the search service could query the cache before it updates. This also significantly compilcates your subscription model, as you now have two event streams for a single service with some overlap in update events.
I’d personally probably go with option 1, just because it has the least caveats, but any of these would work for our purposes.
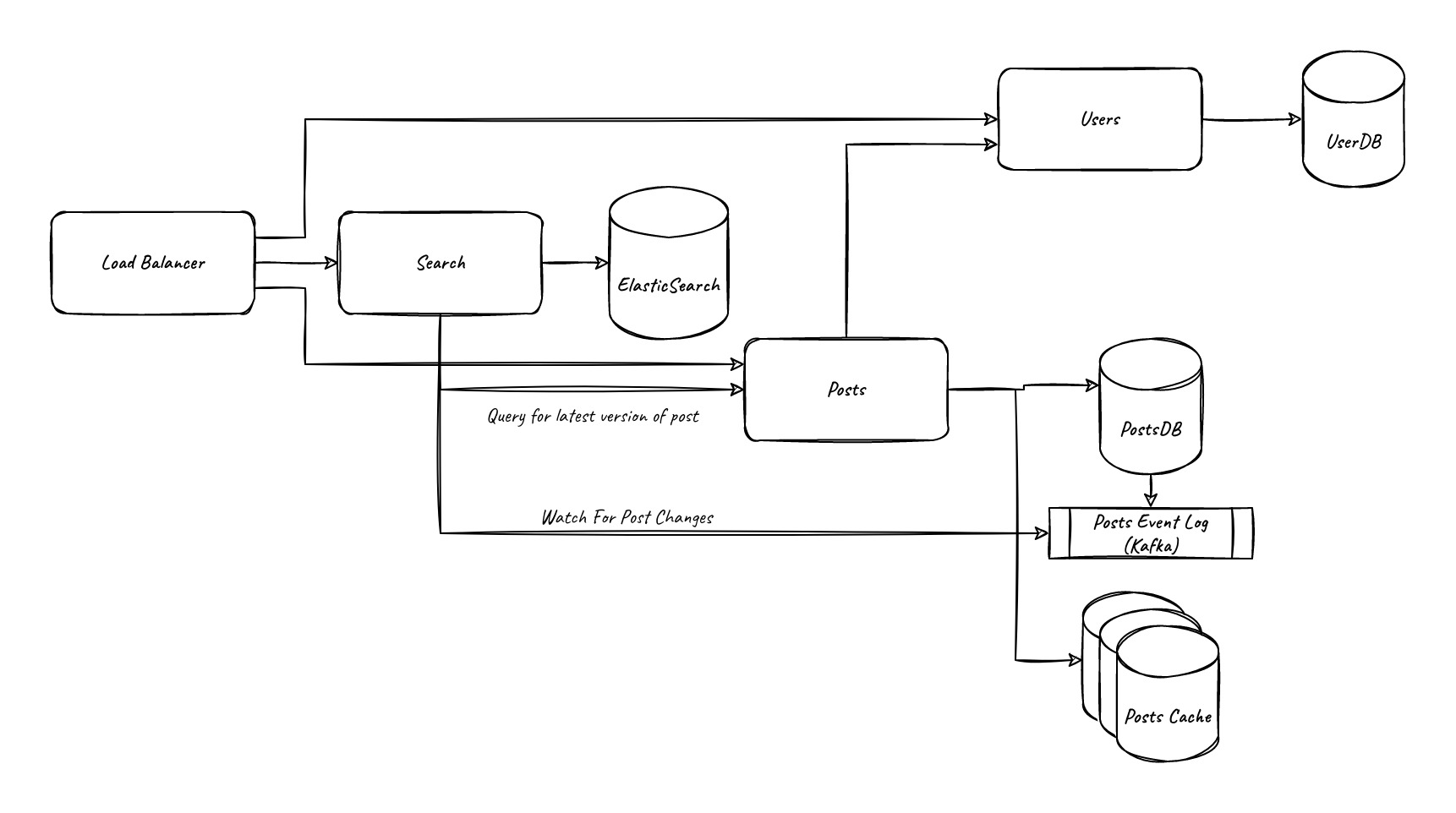
Let’s keep scaling
Our search service can be scaled horizontally, our API and cache can be scaled horizontally, which mostly just leaves our database. As much as we like to pretend traditional single-node RDBMSs aren’t single points of failure, they will commonly be the highest point of contention, and when scaling we’ll engineer around them so they can receive as few queries as possible.
The next three bottlenecks we’ll run into are likely:
- List GET queries, which are not currently cached because they’re not key/value.
- Database cannot hold everything in RAM due to storing the full text rather than just the metadata.
- Write contention, from too many people posting or updating posts at once.
If you are frequently performing searches with a fixed set queries without filters, such as listing a popular user’s posts, you can cache that query to a key/value store. Since storing that for every user would be expensive we could utilize a random eviction strategy on the cache. If you are frequently performing searches with filters and for more users than would fit in the cache this would be a good time to introduce read-replicas to your architecture. Read-replicas are read-only versions of your database that get replicated to and can query over your indexes and full data set at the expense of being a delayed cache.
When scaling a database, you can only efficiently query what’s stored in RAM, and with posts being up to 1 MB in size you can quickly scale beyond that. We could move to only storing the metadata in the database, and move the text to be stored in a larger scale system like s3 by post id, and keep a random eviction cache of post contents in redis. This allows us to store an unlimited amount of data, with quick retrieval on the most popular posts thanks to the cache.
For write contention, scale the database as vertically as possible, once you run into the limits of vertical scaling you can either switch to a Document datastore, a NewSQL datastore, or start sharding. Both document and NewSQL datastores will spread the data across multiple nodes allowing you to begin scaling horizontally once you being running into the vertical limits, at the expense of either losing some guarantees around consistency, or needing a form of distributed consensus which adds latency to your writes. For sharding, you’ll run multiple databases and split the data between them based on shard key, the problem then becomes picking the shard key. Picking a shard key can be a hard problem, as it can greatly affect your querying performance. If you pick the post’s id as the shard key, you can expect posts to be evenly distributed between shards, so you don’t really have to worry about balancing as much, but if you want to query all posts from an author you’ll have to hit every shard and join the results. If you shard by author_id you risk the stores becoming unbalanced, but you’ll be able to only query a single shard.
Now that we’ve implemented these changes, every part of the system including the database should be able to scale with size/load so we shouldn’t see any bottlenecks short of extreme “you are the most popular blogging platform on the planet” scale.